 driftless
pre-seed · 2026
driftless
pre-seed · 2026
Make every AI agent work like it knows your company.
Driftless keeps what your company knows, operates, and ships in one governed system.
jose@driftless.icu · driftless.icu
driftless 02Context gets lost because agents don’t have a workspace to operate in.
- Knowledge lives in docs, Slack, code, and people’s heads.
- Operations live in CRMs, spreadsheets, trackers, and inboxes.
- Work moves through tickets, chats, pull requests, and meetings.
- Agents can chat, but they cannot reliably see or move the workspace.
 driftless 03
driftless 03Driftless makes agentic workflows easy and accessible for companies.
- Integrate every provider in our workspace.
- Navigate end-to-end through Driftless across 100+ providers.
- Run agent-native workflows from the same shared system.
- Let context compound as your team works over time.
- Keep humans in control of what agents can trust and do.
 Slack
Slack GitHub
GitHub Notion
Notion Linear
Linear Salesforce
Salesforce Drive
Drive Gmail
Gmail Claude
Claude ChatGPT
ChatGPT Cursordriftless 04
Cursordriftless 04Agent-native workspaces are priced to expand with the team.
Free gets agents into the repo. Pro converts solo builders. Team starts at $49/month for 5 seats, then expands with seats, workspaces, and integrations. Enterprise is custom for orgs that want Driftless as a governed system of record.
Pricing-backed scenario, not a top-down TAM: Team starts at $49/mo, expands with seats/workspaces, and Enterprise moves blended workspace ARPA into the hundreds.
driftless 05Software was built for humans. Agents need a new type of workspace.
The SaaS stack is fragmented.
Companies run on dozens to hundreds of apps, each with its own UI, permissions, records, and workflow.
Humans bridge the gaps with meetings, Slack, docs, dashboards, and copy-paste.
Dashboards assume a human operator.
Agents do not want another UI. They need context and one governed workspace to operate across the company.
driftless 06Teams and agents are already using Driftless as a workspace.
“Every decision, every constraint, every mistake we already made — anchored to the code. No one has to explain it again.”
“Driftless became our team's technical memory... one of those tools that becomes indispensable fast.”
Next milestone: convert early activation into retained weekly workspace workflows.
driftless 07Context creates gravity. Work moves toward Driftless.
Decisions, records, workflows, and outcomes become reusable by the next agent.
External tools stay in place, but Driftless becomes the governed way agents operate across them.
As more work runs through Driftless, the workspace becomes harder to replace.
The more work Driftless runs, the more context it owns. The more context it owns, the better every agent gets.
driftless 08 driftless 09
driftless 09But wait — context delivery is the wedge into agent outcomes.
The first product is a workspace. The bigger opportunity is letting agents safely operate across company workflows and produce governed outcomes.
5M company workspaces × ~$399/month Team + Enterprise.
50M governed workflows × ~$50/month across engineering, support, revenue, and ops.
Gartner estimates agentic AI can disrupt up to $234B of application spend by 2030.
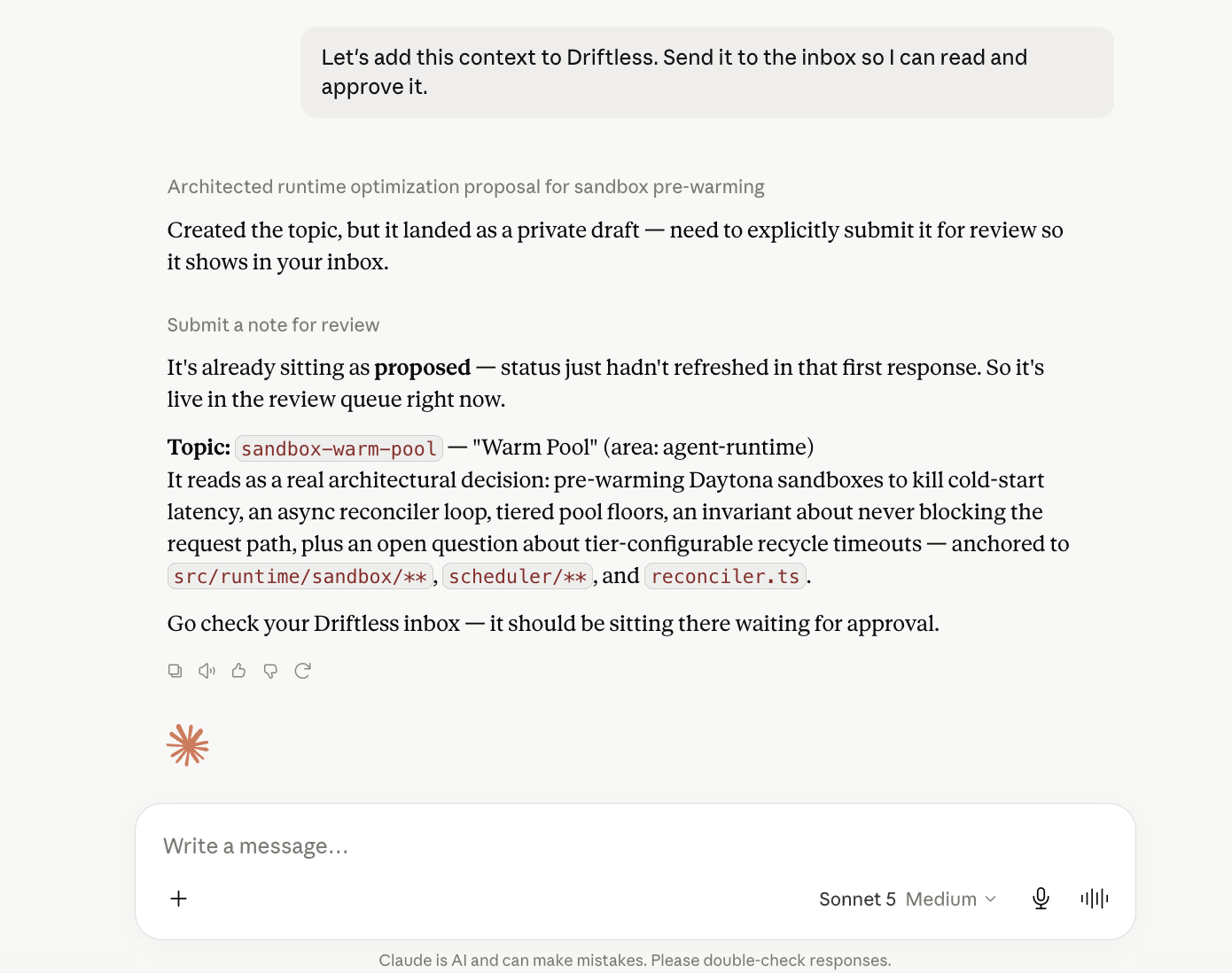
Agents propose useful context, then humans approve what becomes trusted.

Projects turn goals, specs, and acceptance criteria into executable work.
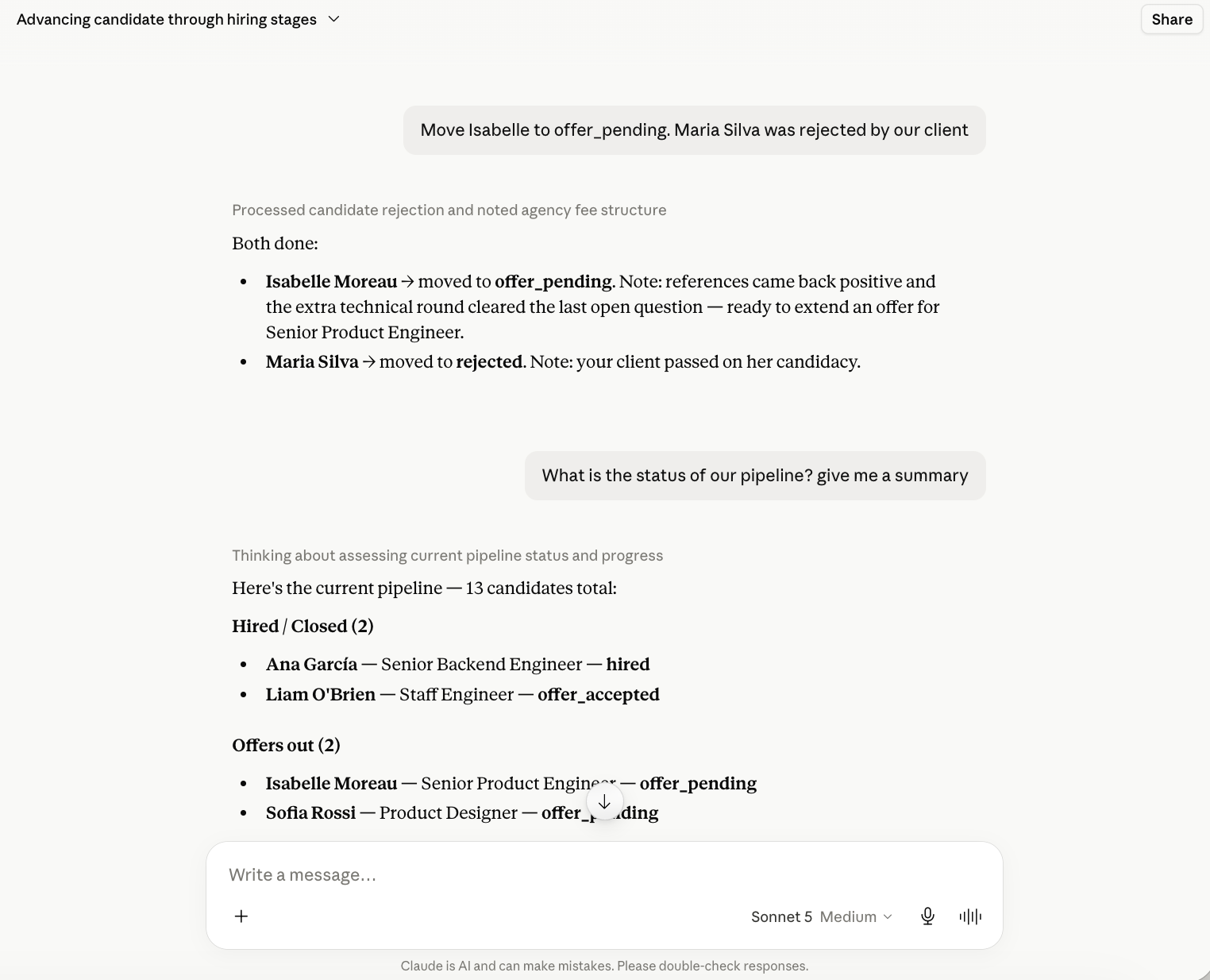
Collections make pipelines, records, and queues readable and movable by agents.
driftless 10Make every AI agent work like it knows your company.
The platform is live. The next step is turning early agent adoption into retained team workflows.
jose@driftless.icu · driftless.icu